在 NoSQL 方面,之前了解到百度对 Hadoop 和 hypertable 都有研究,而且 hypertable 方面更是作为其主要赞助商之一,但之前和百度的一些朋友了解到百度内部对 hypertable 倒是使用不多,相反在 Hadoop 方面倒是有比较大的应用实例。下面一篇文章描述了百度内部4000个结点的 Hadoop 集群的一些技术细节。
百度的高性能计算系统(主要是后端数据训练和计算)目前有4000节点,超过10个的集群,最大的集群规模在1000个节点以上。每个节点由8核CPU以及16G内存以及12TB硬盘组成,每天的数据生成量在3PB以上。规划当中的架构将有超过1万个节点,每天的数据生成量在10PB以上。
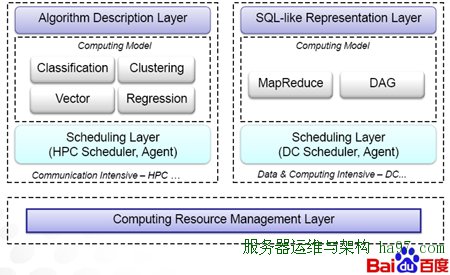
底层的计算资源管理层采用了Agent调度不同类型的计算分别给MPI结构的算法和Map-Reduce和DAG算法应用等。而通过调度的分配,可以让HPC高性能计算集群和大规模分布式集群各得其所的计算相应数据。
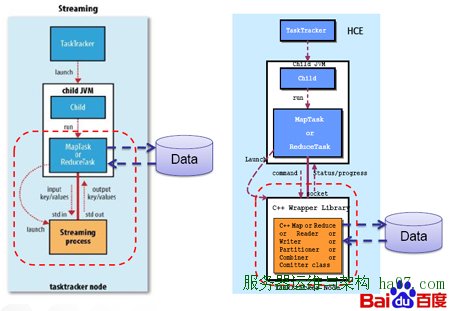
百度通过HCE对streaming作业的排序,压缩,解压缩,内存控制进行了优化并提供了C++版的MapReduce接口。
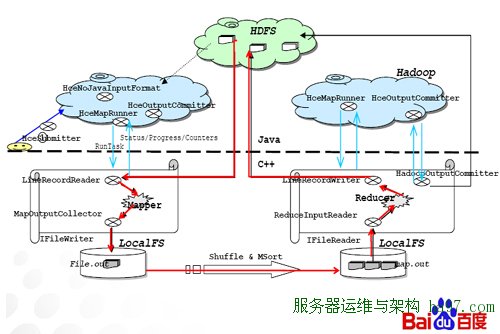
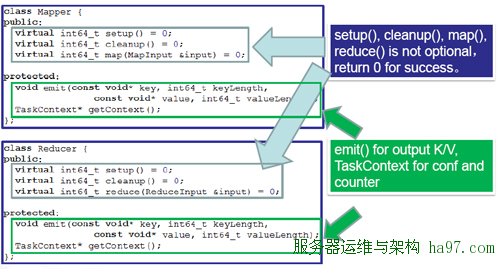
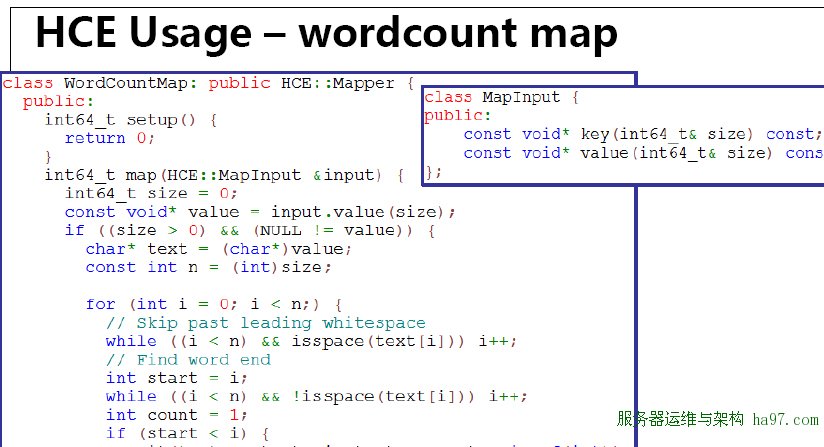

百度HCE语言的有关内容,HCE是基于C++的Hadoop环境,是一个全功能C++环境,可以避开Java语言对于释放内存和资源申请的弊端,并在调用数据时绕开Java语言的所有关节,极大的提升算法效率。

百度的调度器是在capacity-scheduler的基础上根据自身业务改进的。

百度计划对shuffle流程进行大幅改造
转自:http://www.cnblogs.com/chinacloud/archive/2010/11/08/1871592.html
Hadoop的知名应用项目请参考:
http://wiki.apache.org/hadoop/PoweredBy