【二】Chrome的进程间通信
1. Chrome进程通信的基本模式
进程间通信,叫做IPC(Inter-Process Communication),在Chrome不多的文档中,有一篇就是介绍这个的,在这里。Chrome最主要有三类进程,一类是Browser主进程,我们一直尊称它老人家为老大;还有一类是各个Render进程,前面也提过了;另外还有一类一直没说过,是Plugin进程,每一个插件,在Chrome中都是以进程的形式呈现,等到后面说插件的时候再提罢了。Render进程和Plugin进程都与老大保持进程间的通信,Render进程与Plugin进程之间也有彼此联系的通路,唯独是多个Render进程或多个Plugin进程直接,没有互相联系的途径,全靠老大协调。。。
进程与进程间通信,需要仰仗操作系统的特性,能玩的花着实不多,在Chrome中,用到的就是有名管道(Named Pipe), 只不过,它用一个IPC::Channel类,封装了具体的实现细节。Channel可以有两种工作模式,一种是Client,一种是 Server,Server和Client分属两个进程,维系一个共同的管道名,Server负责创建该管道,Client会尝试连接该管道,然后双发往 各自管道缓冲区中读写数据(在Chrome中,用的是二进制流,异步IO…),完成通信。。。
|
Channel中,有三个比较关键的角色,一个是Message::Sender,一个是Channel::Listener,最后一个是MessageLoopForIO::Watcher。 Channel本身派生自Sender和Watcher,身兼两角,而Listener是一个抽象类,具体由Channel的使用者来实现。顾名思 义,Sender就是发送消息的接口,Listener就是处理接收到消息的具体实现,但这个Watcher是啥?如果你觉得Watcher这东西看上去 很眼熟的话,我会激动的热泪盈眶的,没错,在前面(第一部分第一小节…)说消息循环的时候,从那个表中可以看到,IO线程(记住,在Chrome 中,IO指的是网络IO,*_*)的循环会处理注册了的Watcher。其实Watcher很简单,可以视为一个信号量和一个带有 OnObjectSignaled方法对象的对,当消息循环检测到信号量开启,它就会调用相应的OnObjectSignaled方法。。。
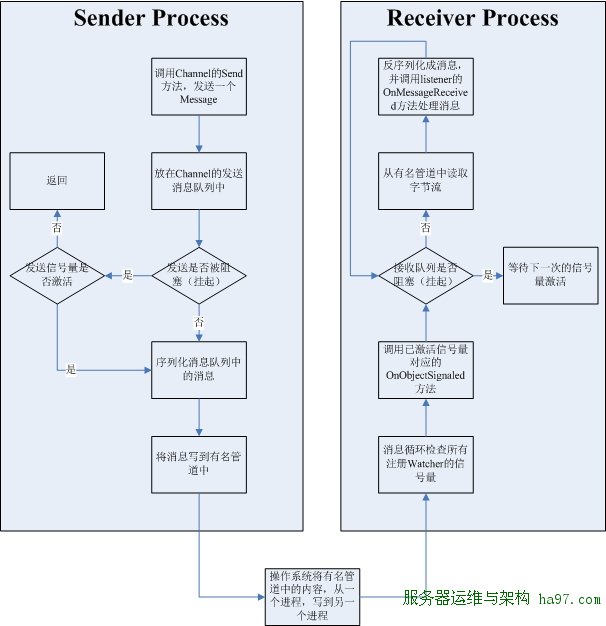
|
| 图5 Chrome的IPC处理流程图 |
一图解千语,如上图所示,整个Chrome最核 心的IPC流程都在图上了,期间,刨去了一些错误处理等逻辑,如果想看原汁原味的,可以自查Channel类的实现。当有消息被Send到一个发送进程的 Channel的时候,Channel会把它放在发送消息队列中,如果此时还正在发送以前的消息(发送端被阻塞…),则看一下阻塞是否解除(用一个等 待0秒的信号量等待函数…),然后将消息队列中的内容序列化并写道管道中去。操作系统会维护异步模式下管道的这一组信号量,当消息从发送进程缓冲区写 到接收进程的缓冲区后,会激活接收端的信号量。当接收进程的消息循环,循到了检查Watcher这一步,并发现有信号量激活了,就会调用该Watcher 相应的OnObjectSignaled方法,通知接受进程的Channel,有消息来了!Channel会尝试从管道中收字节,组消息,并调用 Listener来解析该消息。。。
从上面的描述不难看出,Chrome的进程通信,最核心的特点,就是利用消息循环来检查信号量,而不是直接让管道阻塞在某信号量上。这样就与其多线程模型紧密联系在了一起,用一种统一的模式来解决问题。并且,由于是消息循环统一检查,线程不会随便就被阻塞了,可以更好的处理各种其他工作,从理论上讲,这是通过增加CPU工作时间,来换取更好的体验,颇有资本家的派头。。。
|
2. 进程间的跨线程通信和同步通信
在Chrome中,任何底层的数据都是线程非安 全的,Channel不是太上老君(抑或中国足球?…),它也没有例外。在每一个进程中,只能有一个线程来负责操作Channel,这个线程叫做IO 线程(名不符实真是一件悲凉的事情…)。其它线程要是企图越俎代庖,是会出大乱子的。。。
但是有时候(其实是大部分时候…),我们需要从非IO线程与别的进程相通信,这该如何是好?如果,你有看过我前面写的线程模型,你一定可以想到,做法很简单,先将对Channel的操作放到Task中,将此Task放到IO线程队列里,让IO线程来处理即可。当然,由于这种事情发生的太频繁,每次都人肉做一次颇为繁琐,于是有一个代理类,叫做ChannelProxy,来帮助你完成这一切。。。
从接口上看,ChannelProxy的接口和 Channel没有大的区别(否则就不叫Proxy了…),你可以像用Channel一样,用ChannelProxy来Send你的消 息,ChannelProxy会辛勤的帮你完成剩余的封装Task等工作。不仅如此,ChannelProxy还青出于蓝胜于蓝,在这个层面上做了更多的 事情,比如:发送同步消息。。。
不过能发送同步消息的类不是ChannelProxy,而是它的子类,SyncChannel。在Channel那里,所有的消息都是异步的(在Windows中,也叫Overlapped…),其本身也不支持同步逻辑。为了实现同步,SyncChannel并没有另造轮子,而只是在Channel的层面上加了一个等待操作。当ChannelProxy的Send操作返回后,SyncChannel会把自己阻塞在一组信号量上,等待回包,直到永远或超时。从外表上看同步和异步没有什么区别,但在使用上还是要小心,在UI线程中使用同步消息,是容易被发指的。。。
3. Chrome中的IPC消息格式
说了半天,还有一个大头没有提过,那就是消息包。如果说,多线程模式下,对数据的访问开销来自于锁,那么在多进程模式下,大部分的额外开销都来自于进程间的消息拆装和传递。不论怎么样的模式,只要进程不同,消息的打包,序列化,反序列化,组包,都是不可避免的工作。。。
在Chrome中,IPC之间的通信消息,都是派生自IPC::Message类的。对于消息而言,序列化和反序列化是必须要支持的,Message的基类Pickle,就是干这个活的。Pickle提供了一组的接口,可以接受int,char,等等各种数据的输入,但是在Pickle内部,所有的一切都没有区别,都转化成了一坨二进制流。这个二进制流是32位齐位的, 比如你只传了一个bool,也是最少占32位的,同时,Pickle的流是有自增逻辑的(就是说它会先开一个Buffer,如果满了的话,会加倍这个 Buffer…),使其可以无限扩展。Pickle本身不维护任何二进制流逻辑上的信息,这个任务交到了上级处理(后面会有说到…),但 Pickle会为二进制流添加一个头信息,这个里面会存放流的长度,Message在继承Pickle的时候,扩展了这个头的定义,完整的消息格式如下:
 |
| 图6 Chrome的IPC消息格式 |
其中,黄色部分是包头,定长96个bit,绿色 部分是包体,二进制流,由payload_size指明长度。从大小上看这个包是很精简的了,除了routing位在消息不为路由消息的时候会有所浪费。 消息本身在有名管道中是按照二进制流进行传输的(有名管道可以传输两种类型的字符流,分别是二进制流和消息流…),因此由payload_size + 96bits,就可以确定是否收了一个完整的包。。。
从逻辑上来看,IPC消息分成两类,一类是路由 消息(routed message),还有一类是控制消息(control message)。路由消息是私密的有目的地的,系统会依照路由信息将消息安全的传递到目的地,不容它人窥视;控制消息就是一个广播消息,谁想听等能够听 得到。。。
|
4. 定义IPC消息
如果你写过MFC程序,对MFC那里面一大堆宏 有所忌惮的话,那么很不幸,在Chrome中的IPC消息定义中,你需要再吃一点苦头了,甚至,更苦大仇深一些;如果你曾经领教过用模板的特化偏特化做 Traits、用模板做函数重载、用编译期的Tuple做变参数支持,之类机制的种种麻烦的话,那么,同样很遗憾,在Chrome中,你需要再感受一 次。。。
不过,先让我们忘记宏和模板,看人肉一个消息,到底需要哪些操作。一个标准的IPC消息定义应该是类似于这样的:
class SomeMessage
: public IPC::Message
{
public:
enum { ID = …; }
SomeMessage(SomeType & data)
: IPC::Message(MSG_ROUTING_CONTROL, ID, ToString(data))
{…}
…
};
大概意思是这样的,你需要从Message(或者其他子类)派生出一个子类,该子类有一个独一无二的ID值,该子类接受一个参数,你需要对这个参数进行序列化。两个麻烦的地方看的很清楚,如果生成独一无二的ID值?如何更方便的对任何参数可以自动的序列化?。。。
在Chrome中,解决这两个问题的答案,就是 宏 + 模板。Chrome为每个消息安排了一种ID规格,用一个16bits的值来表示,高4位标识一个Channel,低12位标识一个消息的子id,也就是 说,最多可以有16种Channel存在不同的进程之间,每一种Channel上可以定义4k的消息。目前,Chrome已经用掉了8种 Channel(如果A、B进程需要双向通信,在Chrome中,这是两种不同的Channel,需要定义不同的消息,也就是说,一种双向的进程通信关 系,需要耗费两个Channel种类…),他们已经觉得,16bits的ID格式不够用了,在将来的某一天,估计就被扩展成了32bits的。书归正 传,Chrome是这么来定义消息ID的,用一个枚举类,让它从高到低往下走,就像这样:
enum SomeChannel_MsgType
{
SomeChannelStart = 5 << 12,
SomeChannelPreStart = (5 << 12) – 1,
Msg1,
Msg2,
Msg3,
…
MsgN,
SomeChannelEnd
};
这是一个类型为5的Channel的消息ID声 明,由于指明了最开始的两个值,所以后续枚举的值会依次递减,如此,只要维护Channel类型的唯一性,就可以维护所有消息ID的唯一性了(当然,前提 是不能超过消息上限…)。但是,定义一个ID还不够,你还需要定义一个使用该消息ID的Message子类。这个步骤不但繁琐,最重要的,是违反了 DIY原则,为了添加一个消息,你需要在两个地方开工干活,是可忍孰不可忍,于是Google祭出了宏这颗原子弹,需要定义消息,格式如下:
IPC_BEGIN_MESSAGES(PluginProcess, 3)
IPC_MESSAGE_CONTROL2(PluginProcessMsg_CreateChannel,
int /* process_id */,
HANDLE /* renderer handle */)
IPC_MESSAGE_CONTROL1(PluginProcessMsg_ShutdownResponse,
bool /* ok to shutdown */)
IPC_MESSAGE_CONTROL1(PluginProcessMsg_PluginMessage,
std::vector<uint8> /* opaque data */)
IPC_MESSAGE_CONTROL0(PluginProcessMsg_BrowserShutdown)
IPC_END_MESSAGES(PluginProcess)
这是Chrome中,定义 PluginProcess消息的宏,我挖过来放在这了,如果你想添加一条消息,只需要添加一条类似与IPC_MESSAGE_CONTROL0东东即 可,这说明它是一个控制消息,参数为0个。你基本上可以这样理解,IPC_BEGIN_MESSAGES就相当于完成了一个枚举开始的声明,然后中间的每 一条,都会在枚举里面增加一个ID,并声明一个子类。这个一宏两吃,直逼北京烤鸭两吃的高超做法,可以参看ipc_message_macros.h,或 者看下面一宏两吃的一个举例。。。
|
此外,当接收到消息后,你还需要处理消息。接收消息的函数,是IPC::Channel::Listener子类的OnMessageReceived函数。在这个函数中,会放置一坨的宏,这一套宏,一定能让你想起MFC的Message Map机制:
IPC_BEGIN_MESSAGE_MAP_EX(RenderProcessHost, msg, msg_is_ok)
IPC_MESSAGE_HANDLER(ViewHostMsg_PageContents, OnPageContents)
IPC_MESSAGE_HANDLER(ViewHostMsg_UpdatedCacheStats,
OnUpdatedCacheStats)
IPC_MESSAGE_UNHANDLED_ERROR()
IPC_END_MESSAGE_MAP_EX()
这个东西很简单,展开后基本可以视为一个Switch循环,判断消息ID,然后将消息,传递给对应的函数。与MFC的Message Map比起来,做的事情少多了。。。
通过宏的手段,可以解决消息类声明和消息的分发 问题,但是自动的序列化还不能支持(所谓自动的序列化,就是不论你是什么类型的参数,几个参数,都可以直接序列化,不需要另写代码…)。在C++这种 语言中,所谓自动的序列化,自动的类型识别,自动的XXX,往往都是通过模板来实现的。这些所谓的自动化,其实就是通过事前的大量人肉劳作,和模板自动递 推来实现的,如果说.Net或Java中的自动序列化是过山轨道,这就是那挑夫的骄子,虽然最后都是两腿不动到了山顶,这底下费得力气真是天壤之别啊。具 体实现技巧,有兴趣的看看《STL源码剖析》,或者是《C++新思维》,或者Chrome中的ipc_message_utils.h,这要说清楚实在不 是一两句的事情。。。
总之通过宏和模板,你可以很简单的声明一个消 息,这个消息可以传入各式各样的参数(这里用到了夸张的修辞手法,其实,只要是模板实现的自动化,永远都是有限制的,在Chrome的模板实现中,参数数 量不要超过5个,类型需要是基本类型、STL容器等,在不BT的场合,应该够用了…),你可以调用Channel、ChannelProxy、 SyncChannel之类的Send方法,将消息发送给其他进程,并且,实现一个Listener类,用Message Map来分发消息给对应的处理函数。如此,整个IPC体系搭建完成。。。
|
作者:duguguiyu
本人重新排版~~
- Google Chrome源码剖析【五】:插件模型
- Google Chrome源码剖析【四】:UI绘制
- Google Chrome源码剖析【三】:进程模型
- Google Chrome源码剖析【二】:进程通信
- Google Chrome源码剖析【一】:多线程模型
- Google Chrome源码剖析【序】