Wikipedia.org 是个标准的运行在 LAMP 上的高流量网站,看看能从 Brion Vibber (CTO, Wikimedia Founation)的这篇讲义:Scaling and Managing LAMP at Wikimedia 学到些什么。(图片资源来自:Scaling and Managing LAMP at Wikimedia)
数据
每个月100亿 PV(日均PV3亿多)
高峰时后每秒达 50000 http requests
约400台 x86 服务器,约250台是 Web Server,剩下的基本上是 MySQL Server
只有7个工程师维护
每个月35000美元的带宽和 hosting 费用
LAMP
Wikipedia 是架在标准 LAMP 上的一个非常好的示例,以下是 Wikipedia.org 用到的一些 stack:
多个不同版本的 Linux,Ubuntu,Debian 等
Apache
PHP
MySQL
Cache
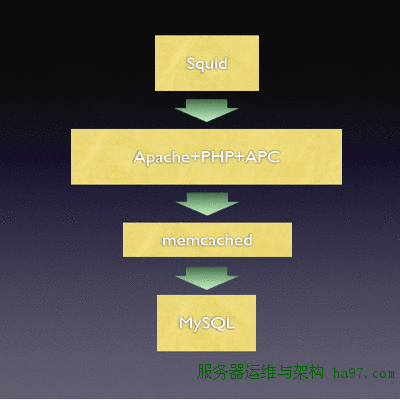
缓存就不用说了,从前端的 web cache,中间的 opcode cache,到后端的 database cache 都需要。Wikipedia 用 Squid + APC + memcached 来完成 cache 工作。Squid 对 wiki 这种内容为主,不经常变化的相对静态的 web 应用很有效。Wikipedia 还用 Squid 做 geographic load balancing,根据不同地理位置访问各地的服务器。只要用到 PHP 的地方就应该用到 opcode cache,Wikipedia.org 选择了 APC,good choice!,VPSee.com 也用 APC:)。memcached 用来缓存数据库的临时 object,不用反复从数据库读取,而且 memcached 可以做成缓存服务器供网上 share object,其他的服务器可以直接读取,比起从磁盘重新读取数据库,网络读取的延迟要小多了。现在大家都用 cache,送礼就送 cache(cash?)!
Scaling
下图中一个服务器上是 MySQL,一个是 memcached,错开分布,每个服务器上的一小部分 memcached 合起来就很可观了。硬盘空间可以用来做冗余,牺牲一点点 CPU 性能来换取较高的可靠性,值!,硬盘便宜,而且 CPU 通常都不是性能瓶颈。
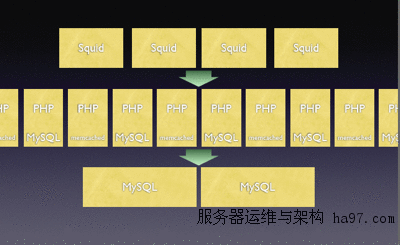
DB Sharding
水平分(Horizontal Sharding):把不相关的 wiki 分给不同的数据库。

垂直分(Vertical Sharding):把 page/links/users 等分一边,大段的 text 分一边。

DB Scaling/Replicatation
设置 MySQL 的 Master-Slave 架构做读写分离,用1台 Master 服务器负责写入数据库,用几台 Slave 同时提供读取,写 Wiki 的人肯定比看 Wiki 的人要少。为了更好的性能,在硬件上可以再做一下调整,Slave 机器的硬件配置应该比 Master 的配置要高一点,这样 Slave 才能跟上 Master,尤其是磁盘 IO,Slave 写入要比 Master 快一点才好。

DB Reliability
一个 Master 坏了,对应的一个 Slave 能自动接管 Master 吗?MySQL 目前不支持自动 failover。
作者:vpsee